KeyCollector (Кей Коллектор): составление семантического ядраОпубликовано: 07.03.2024  Семантическое ядро - основа успешного продвижения любого интернет-проекта. Поэтому важно уделить этому этапу максимально пристальное внимание. Для этого можно воспользоваться наиболее популярной программой для сбора ключевых поисковых запросов - KeyCollector. Key Collector. Урок 1. Установка и настройка Напомню, что в ранее опубликованной статье шла речь о правильном бесплатном подборе ключевых слов для сайта вручную с помощью сервиса статистики Яндекс, то сейчас я рассмотрю процесс составления семантического ядра с помощью специализированного программного комплекса. КейКоллектор - это платная программа , но стоит каждого потраченного на ее приобретение доллара. Это действительно отличный и мощный парсер самых разных показателей, начиная от ключевых слов, ставок в Яндекс.Директ и Google.Adwords, проверки геозависимости и корректности словоформ, уровня конкуренции и заканчивая расширенным анализом данных ведущих SEO-агрегаторов. В одном статье просто невозможно описать все возможности программы, поэтому сейчас я остановлюсь на важнейшей из них – профессиональное составление семантического ядра. Методов подбора, фильтрации и группировки запросов может быть довольно много, но я опишу процесс подбора ключей с помощью Кей Коллектора именно так, как я «наловчился» делать с минимальными затратами времени и с достижением необходимого результата. Обычно на подбор ключей для одной продвигаемой темы у меня уходит около 10-15 минут. Итак, приступим. Создаем проект.Сразу же при открытии Key Collector предложит создать новый проект или открыть старый. В одном проекте целесообразно подбирать и хранить ключевые запросы для всего сайта, если он относительно небольшой, например, до 1000 страниц. Поэтому у меня названием проект обычно является название сайта. Так что создаем новый проект, сохраняем его под любым именем и первым делом указываем адрес сайта вверху страницы в поле URL.
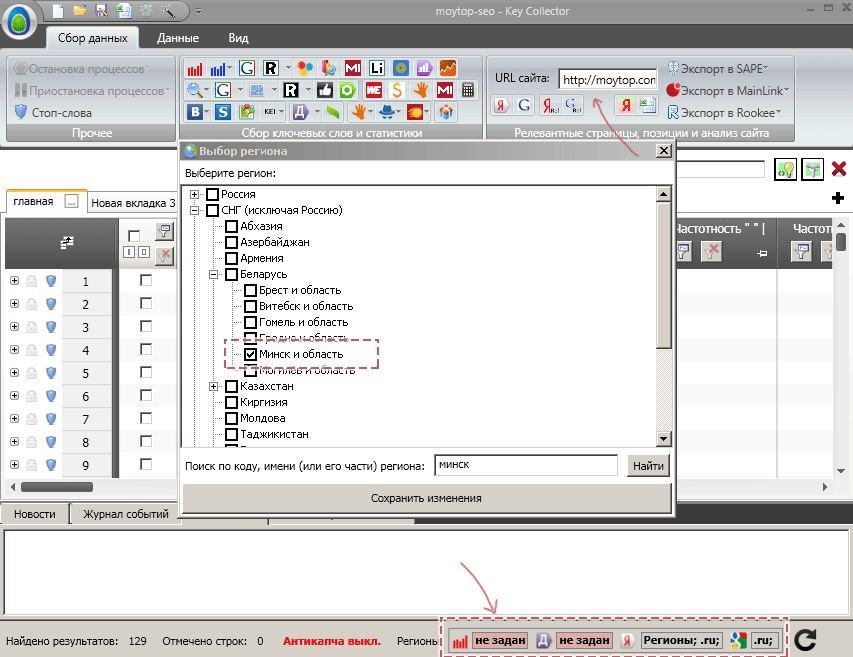
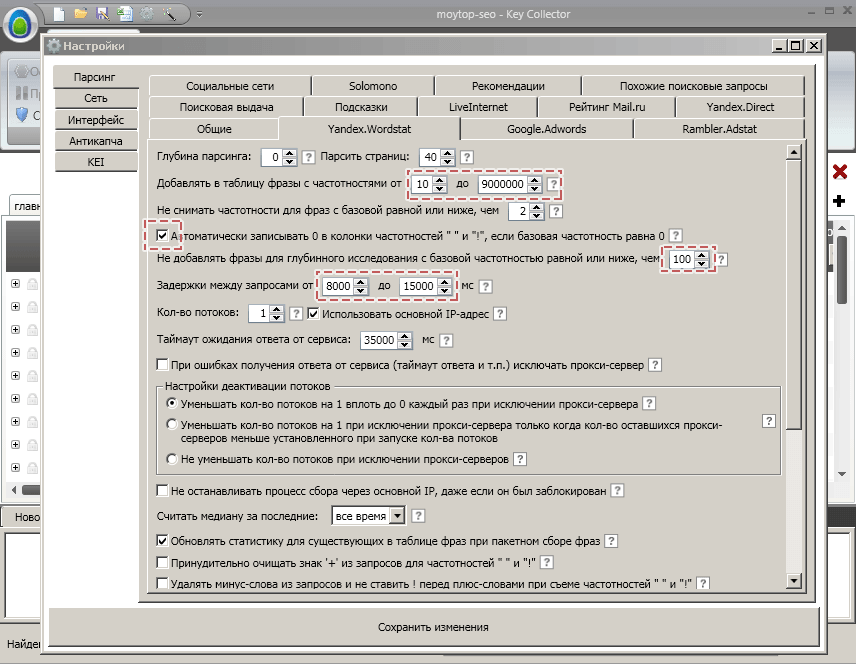
Далее указываем регион, где нужно собирать запросы. Для этого кликаем внизу программы на каждую кнопку Регионы (всего их 4) и выбираем в появившемся окне нужный регион. Первая кнопка будет нам нужна для сбора статистики и словоформ из Яндекс.Вордстат, вторая – для получения частотностей из Яндекс.Директа, третья – для анализа уровня конкурентности и последняя для сбора статистики из Google. Основные настройки.Теперь нужно настроить съем статистики с Яндекс. Он и по умолчанию настроен, но нужно внести небольшие изменения в зависимости от конкретной задачи по составлению семантического ядра. Во-первых, укажите нижнюю границу частотностей для добавляемых фраз. Это делается в пункте «Добавлять в таблицу фразы с частотностями от». Если ваша цель собрать тысячи низкочастотных запросов – ставьте примерный диапазон 5-50 . Если нужно собирать высокочастотные запросы, то ставьте нижнюю границу частотностей от 50 . Во всех остальных случаях подойдет параметр по умолчанию – от 10 .
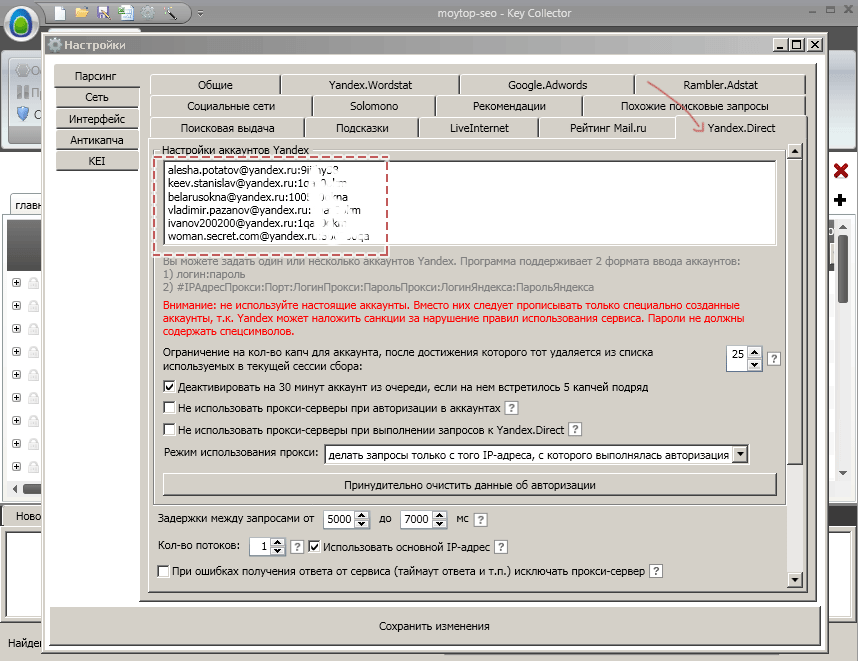
Имеет смысл поставить флажок «Автоматически записывать 0». В этом случае при сборе некоторых низкочастотных запросов не будет пустых результатов. Вы наверное обратили внимание, что глубину парсинга мы оставили равной 0. Нет смысла при сборе обычных региональных запросов использовать большую глубину, так как запросов обычно меньше, чем 40 страниц, которые установлены по умолчанию. Глубину 1 имеет смысл ставить только если стоит задача собрать максимум релевантных ключей по очень высокочастотным запросам и при этом обязательно нужно указать приличное значение, например, 100 в пункте «Не добавлять фразы для глубинного исследования с базовой частотностью равной или ниже, чем». Я обычно немного повышаю задержки между запросами. При значениях 8000-15000 у меня каптча без всяких прокси-серверов ни разу не появлялась, а скорость работы более чем приемлемая. Остается только открыть в этих же настройках вкладку Yandex.Direct и добавить 5-6 специально созданных фейковых аккаунтов в виде адрес:пароль.
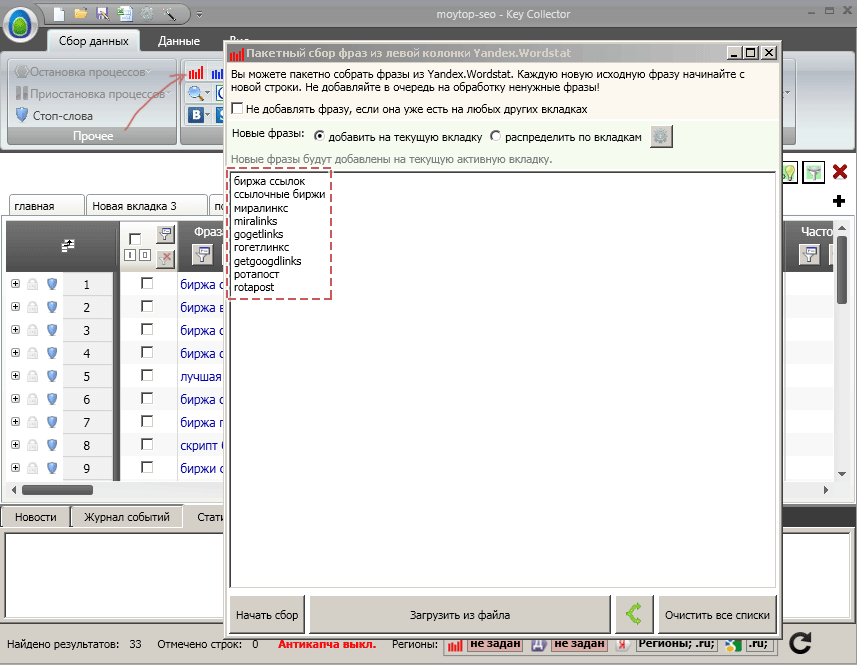
Программа настроена и готова к сбору ключевых слов. Сбор ключевых фраз.Лично мне наиболее удобно собирать ключевые слова для определенной страницы. Хотя некоторые SEO-оптимизаторы предпочитают сначала собрать тысячи фраз, а затем раскидать их по страницам с помощью фильтров. Я в данной статье рассмотрю именно первый вариант, так как он более простой и, на мой взгляд, более правильный и предпочтительный при составлении ядра для продвижения обычных бизнес-сайтов или того же блога. Кликаем на иконку сбора статистики Яндекс.Вордстат и вводим список ключей, которые подходят для продвигаемой страницы или раздела сайта. Тут нужно немного проявить фантазию и придумать всевозможные слова, которые могут отражать суть вашей страницы и по которым потенциальные посетители могут искать продвигаемые сайт в поиске. Если с фантазией туго, просто вручную найдите примеры подобных поисковых запросов в том же Яндексе, как я писал вот здесь . Конечно, можно собрать подсказки с помощью этой же программы KeyCollector, но при составлении семантического ядра для конкретного раздела или страницы обычно это излишне и быстрее просто вбить несколько общих слов, обычно их немного, всего 5-10 для каждой продвигаемой страницы. Заботиться об окончаниях или словоформах не нужно, программа найдет все варианты – просто вбивайте максимально общие, но подходящие по смыслу и исключающие другие трактования слова. Пример. Для статьи по обзору бирж вечных ссылок я изначально использовал вот такие слова:
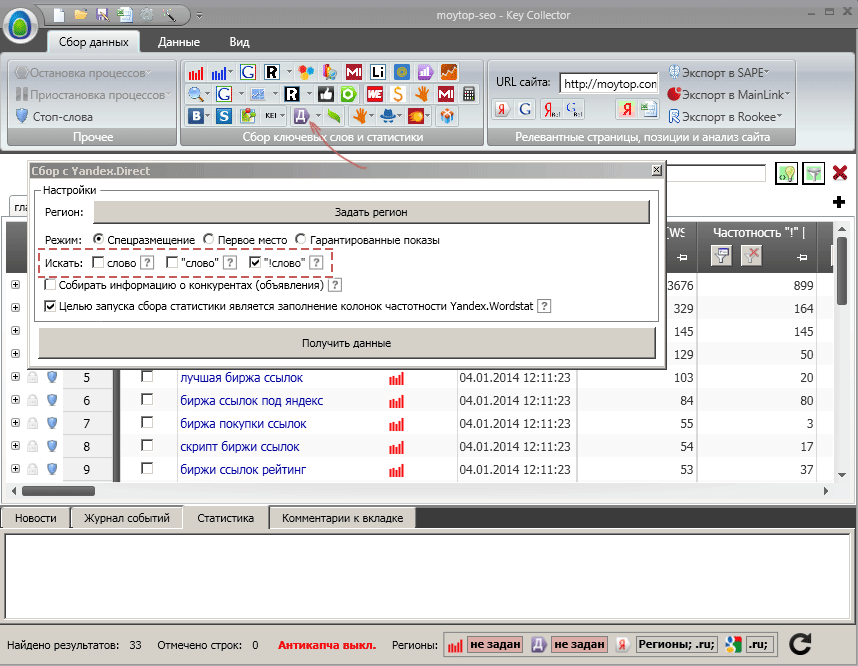
Если бы я использовал только слово «биржа», то программа бы выдала много мусора, который не подходит по содержанию к моей статье, например, про акции, биржевые спекуляции, биржи труда и т.п. А по запросу «биржа ссылок» были найдены самые разные сочетания, при этом хорошо подходящие для моей страницы, в том числе, «лучшая биржа ссылок», «биржи вечных ссылок» и т.п. В то же время, общее слово «miralinks» лучше всего использовать одно, чтобы найти максимально большое количество вариантов запросов с этим словом: ведь его набирают только те, кто в принципе интересуется именно этой темой и никакой другой. Далее кликайте на «Начать сбор» и процесс, как говорится, пошел. Нужно будет подождать минут 5, когда перестанет светиться красным индикатор "Остановка процессов". Отсеиваем лишнее.После сбора ключевых слов с помощью программы КейКоллектор на текущей вкладке появится список из всех найденных в поисковой статистике фраз, соответствующих настроенным параметрам. Среди них есть два типа ключей, которые не подойдут для продвижения: Ключи, с небольшим количеством прямых вхождений. Ключи, содержащие минус-слова.Ключи с небольшим количеством прямых вхождений.Я уже писал ранее что это такое, сейчас лишь немного повторюсь. Изначально программа собирает ключевые запросы с базовой частотностью . Это означает, что выдаваемое количество того или иного запроса в месяц будет включать в себя все словоформы с этим запросом. Например, запрос «биржа покупки ссылок» = 55 показов в месяц. Но в число этих показов будет входить много вариаций этого запроса, например, «отзывы о бирже покупки ссылок» или «sape биржа покупки ссылок» и т.п. Для продвижения сайта нет возможности использовать сразу все эти варианты, ведь ключевые запросы нужно будет прописать в метатегах, которые очень невелики по объемам, добваить в заголовки и подзаголовки страниц, которые также не резиновый и без переспама с нормальной плотностью вписать в текст.Поэтому логично выбрать наиболее часто встречающиеся запросы и оптимизировать страницу именно под них, чтобы на продвигаемый сайт заходило как можно больше человек. А сколько было показов именно «биржа покупки ссылок» без всяких дополнений и вариаций? Для этого нужно собрать данные с так называемой частотностью «!». Приступаем. Кликаем на иконку Директа, проверяем установку флажка около “!слово” и нажимаем «Получить данные».
Как вы видите, количество прямых запросов ключа «биржа покупки ссылок» совсем невелико – всего 3 (!) запроса в месяц, вместо 55. Значит оптимизировать страницу под этот запрос лично я не вижу смысла. Поэтому важно отсетить все запросы, которые имеют мало прямых точных вхождений в поиске, например, менее 5. Чтобы сделать это быстро, просто отсортируем все собранные ключи по точной частотности «!».
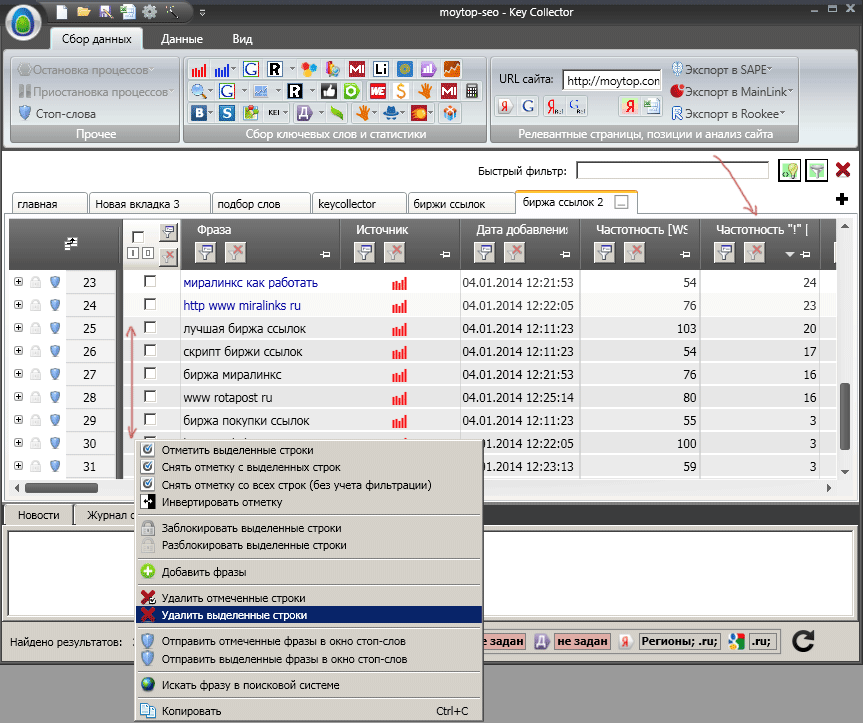
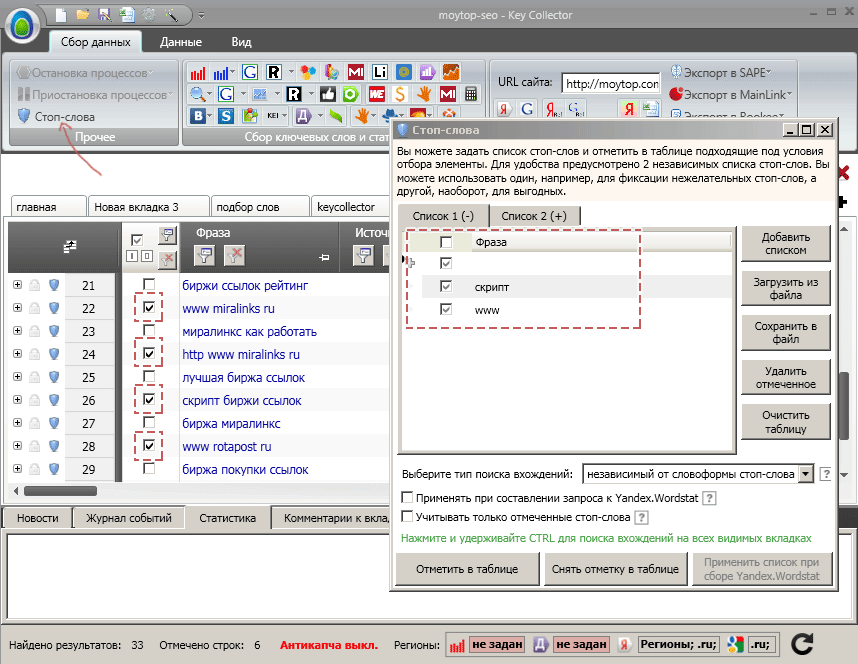
Затем выделим строки, которые содержат слова с недостаточной частотностью и удалим их. 10 секунд, и список из сотен слов обычно сокращается в 3-5 раз. Теперь имеет смысл отбросить оставшиеся нерелевантные ключи.Ключи с минус-словами.Что это такое? Это поисковый запрос, по которому ищут не продвигаемую страницу и очевидно не потенциальные клиенты. Например, для магазина по продаже пылесосов такими нерелевантными запросами могут быть ключи со словами «инструкция», «отзывы», То есть запрос «инструкция к пылесосу самсунг» - вряд ли будет полезен для владельца рядового интернет-магазина, ведь даже если по нему придет много людей, то максимум что они сделают – скачают эту инструкцию, а вовсе не купят новый пылесос.В моем случае имел смысл удалить ключи со словами «скрипт», «www» и т.п. Приступаем. Кликаем на кнопку «Стоп-слова». В появившемся окне вводим минус-слова, убеждаемся что внизу тип поиска вхождений стоит «Независимый от словоформы стоп-слова». Это нужно, чтобы не писать каждое минус-слово в точном соответствии, а использовать более общие минус-слова. В этом случае при использовании, например, минус-слова «инструкц» будут удалены поисковые запросы «пылесосы инструкция», «скачать инструкции к пылесосам» и т.п., то есть запросы с любой словоформой.
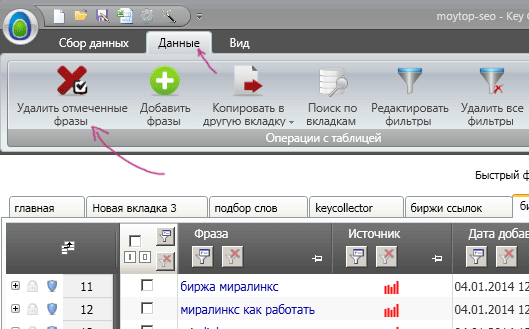
Жмем на «Отметить в таблице» и в результате все ключевые запросы, содержащие минус-слова, становятся отмеченными флажками. Теперь остается только удалить их. Открывайте вверху вкладку «Данные», выбирайте «Удалить отмеченные фразы» и все – теперь вы имеете список ключей без посторонних запросов.
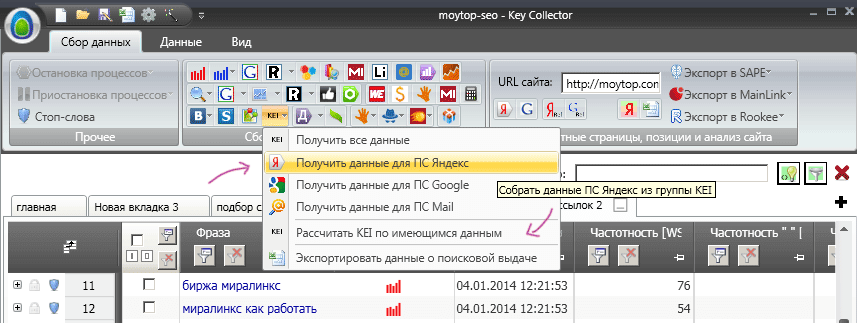
Определяем уровень конкуренции.Отличной возможность программы KeyCollector является парсинг данных о количестве найденных проиндексированных страниц по каждому поисковому запросу, число сайтов в ТОП-10, которые содержат эту ключевую фразу в заголовке страницы Title, а также сколько страниц из первой десятке по этим запросам являются главными страницами. Понятно, что чем больше проиндексированных страниц, оптимизированных заголовков и главных страниц в выдаче, тем сложнее с ними будет конкурировать. Однако очень часто бывает ситуация, когда хорошие высокочастотные запросы имеют сравнительно небольшой уровень конкуренции. Поэтому очень важно проанализировать все собранные ключевые запросы на уровень конкуренции для того, чтобы выбрать и продвигаться по самым выгодным и еще незанятым ключам. Для этого кликаем на иконку «KEI» и выбираем «Получить данные для ПС Яндекс». Можно, конечно, уточнять уровень конкуренции и в других поисковых системах, это зависит от задания на продвижение, но в большинстве случаев Яндекса хватает, чтобы получить объективную картину сложности продвижения того или иного запроса.
Конечно, этот уровень определения конкуренции несовершенен. Было бы просто идеально, чтобы программа умела также парсить по каждому запросу: Средний тИЦ и PR сайтов в ТОП-10. Средний объем страниц. Среднее количество внешних ссылок на конкурента и т.п.В этом случае результат был бы точнее. Но как показывает практика даже такого «беглого» анализа конкуренции достаточно для того, чтобы успешно находить выгодные ключи и быстро по ним продвигаться, так как многие оптимизаторы его не проводят вовсе и в итоге многие сайты продвигаются по сложным конкурентным запросам, хотя рядом «лежат» запросы с не меньшей частотой и с полным отсутствием оптимизированных конкурентов.После парсинга данных, остается только рассчитать индекс уровеня конкуренции (KEI) по определенной формуле, которая обычно индивидуальна у каждого оптимизатора. Вы можете использовать свои наработки или воспользоваться моими. Я их привожу в статье « Как рассчитать формулу KEI ». Чтобы сделать расчет добавьте формулу в настройки программы и просто нажмите «Рассчитать KEI по имеющимся данным». Семантическое ядро готово. Его можно экспортировать в формат Microsoft Excel (*.xls) и немного отредактировать полученные данные. Самые выгодные ключи можно выделить другим цветом. Вот, например, что получилось у меня: Как я уже говорил, KeyCollector - платная программа, цена около 1500 RUB. Но программа того стоит Отбивается она за неделю работы.
Вы можете даже разместить свой аккаунт на Kwork.ru , дать объявления и собирать ключи за деньги. Или же наоборот, можете просто заказывать сбор ключей у тамошних специалистов по 500 руб. и экономить время, если заказов немеряно. Но мне кажется, что лучше один раз заплатить, освоить KeyCollector самому и зарабатывать на нем, хотя бы и на том же Кворке или на Weblancer.net (тут заработки раза в 3 выше, но и биржа платная). P.S. Хотите узнать, как у меня получилось настроить сервис для съема позиций в поиске - так, чтобы он работал бесплатно? Тогда читайте статью по ссылке . |
|


 Добро пожаловать ,
Гость
!
Добро пожаловать ,
Гость
!
 Войти
Войти